
SLAMffusion
SLAM stands for Simultaneous Localization and Mapping, a robotics technique for when you need to use sensor data to accurately build a map and find yourself in it. It's about compensating for noisy data by using constraints like common landmarks and loop closures to either find the most likely solution (particle/Kalman-based) or the least bad solution (graph optimization-based).
Wait. Denoising. Isn't that what diffusion models are really good at? Could SLAM Diffusion or Diffusion SLAM work? Short answer: unfortunately it hasn't for me.
Thing with images is that they're convenient to represent. It's just a grid of pixels. You can split it into its channels, scale it down, or throw it into an autoencoder, but it doesn't get any more complex to handle. But to do SLAM, you need to denoise location, and so you need to denoise trajectories, and so you must represent trajectories somehow. And there are so many ways to do that.
To start, we aren't even adding sensors. The question is just "can the model learn how to generate trajectories that look like what it was trained on". For my purposes, my trajectories were Roomba-like, mostly straight but bouncing off of walls and a divider. Back to representing the trajectories:
- Represent each move as how much the left and right wheels have changed. Or represent it as the sum of all time and hope that the model learns how to make its convolutions subtract. Remember to supplement with dead reckoning since the model won't figure out absolute position from just the wheel data.
- Represent each move as a vector (whether polar or Cartesian). Or an absolute position. Hope this doesn't break the model's model of turning in place.
- Represent each move as a pose (x, y, theta) delta. Or an absolute pose. Hope that implicitly forcing the model to learn sine and cosine isn't problematic.
Even if you have a good representation, you still need to train the model. But how? What will you input? What will be simply conditioned? How will you architecture the insides? What will come out the other end? What do you calculate loss on?
And what type of noise do you add? How do you add (or mix) it? Does the model get to know the step of denoising it's on?
Say you figured out the implementation details, all of this worked, and you now have a model that can denoise a trajectory or create a trajectory from nothingness. Now how do you go the rest of the way, to replacing SLAM? You'll need to somehow make your model learn about loop closures and landmarks from there, likely having to figure out how to use attention. You'll have to also make sure the synthetic noise matches real noise.
Sorry if you were hoping for the usual "I made this!" on this blog. This is truly a skill issue. If I knew more about diffusion or had access to stronger LLMs I could probably make this work. In fact, I might come back to this later and try again. However, for the time being, you can look at how I failed.
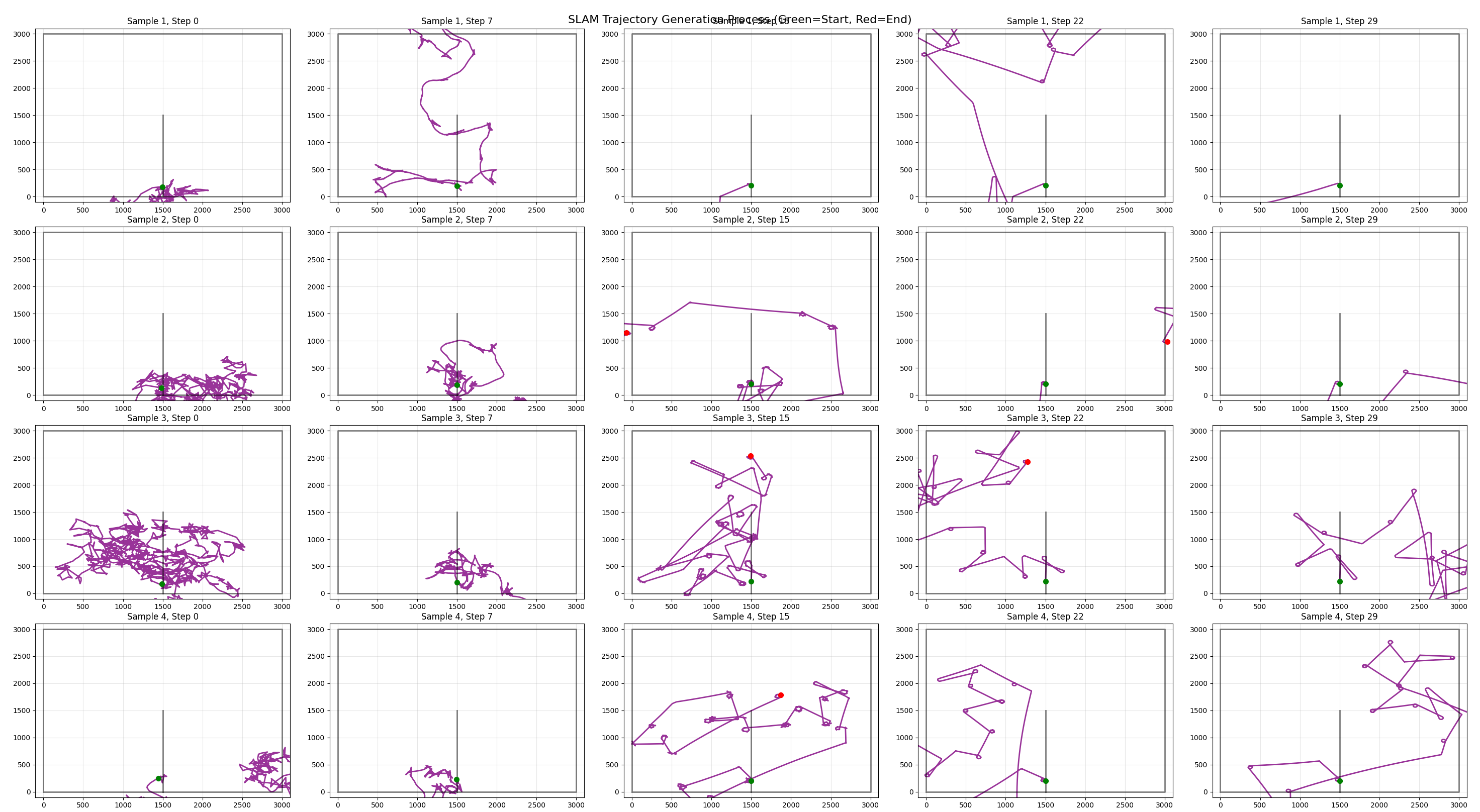
First and best attempt that denoises wheel deltas, conditioned on dead reckoned pose
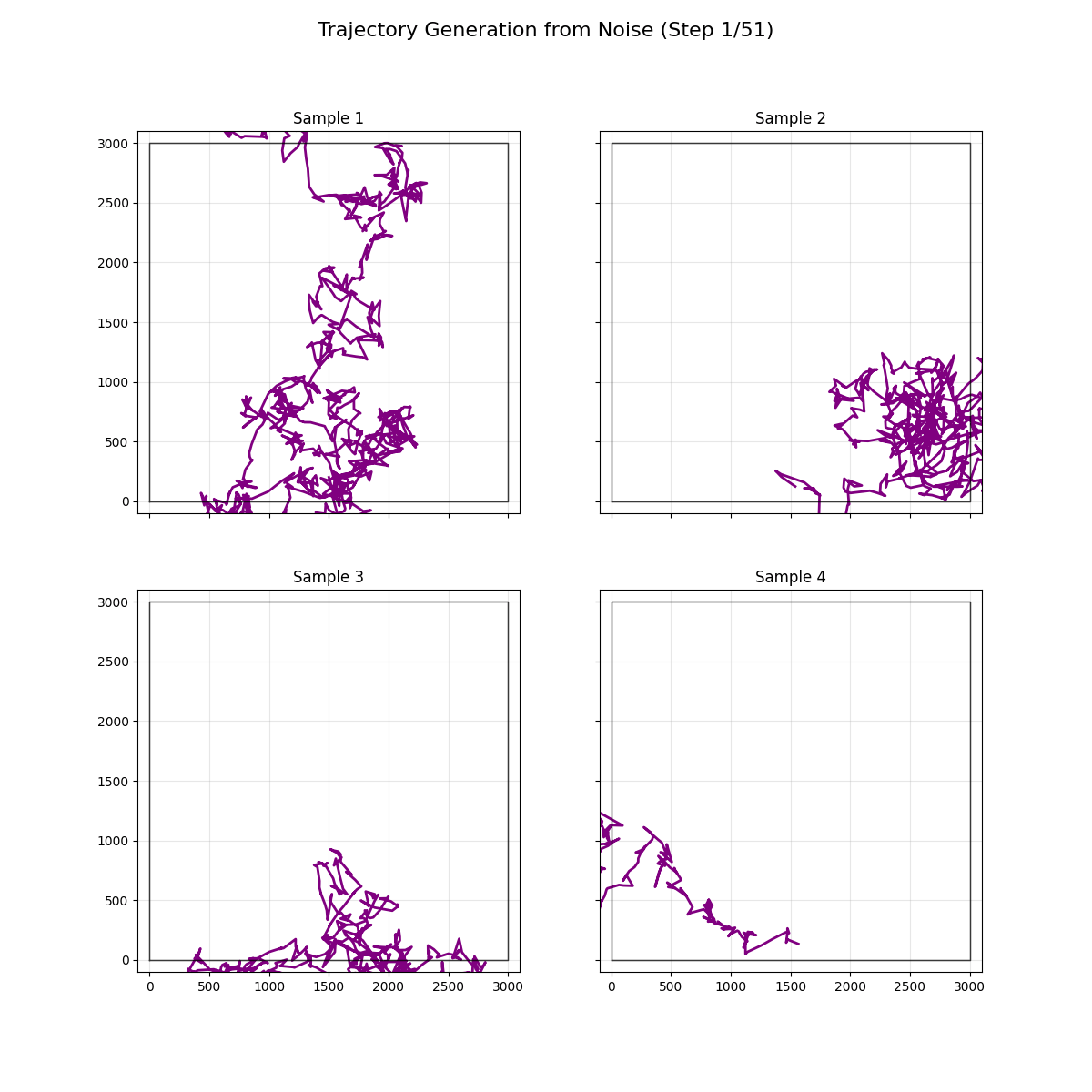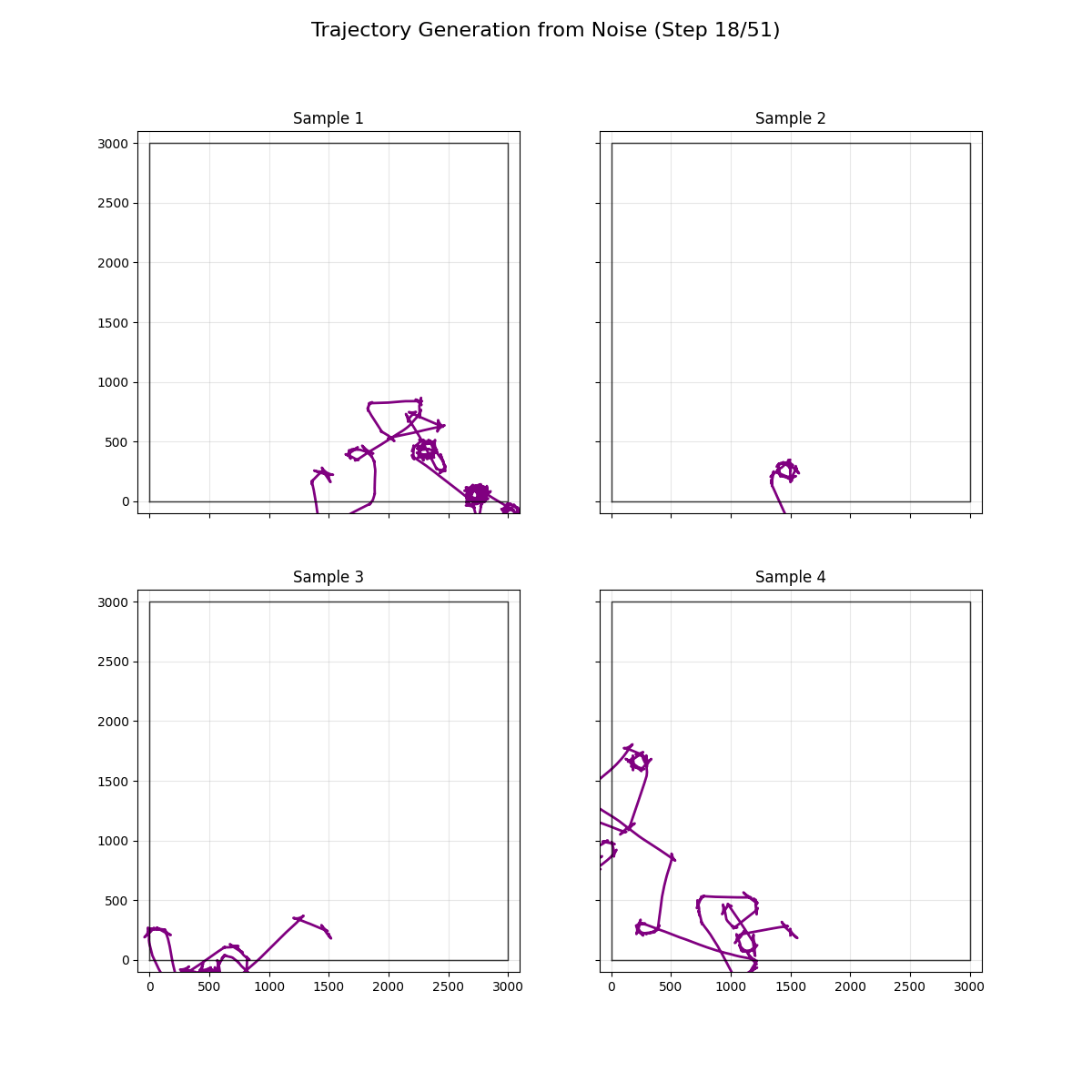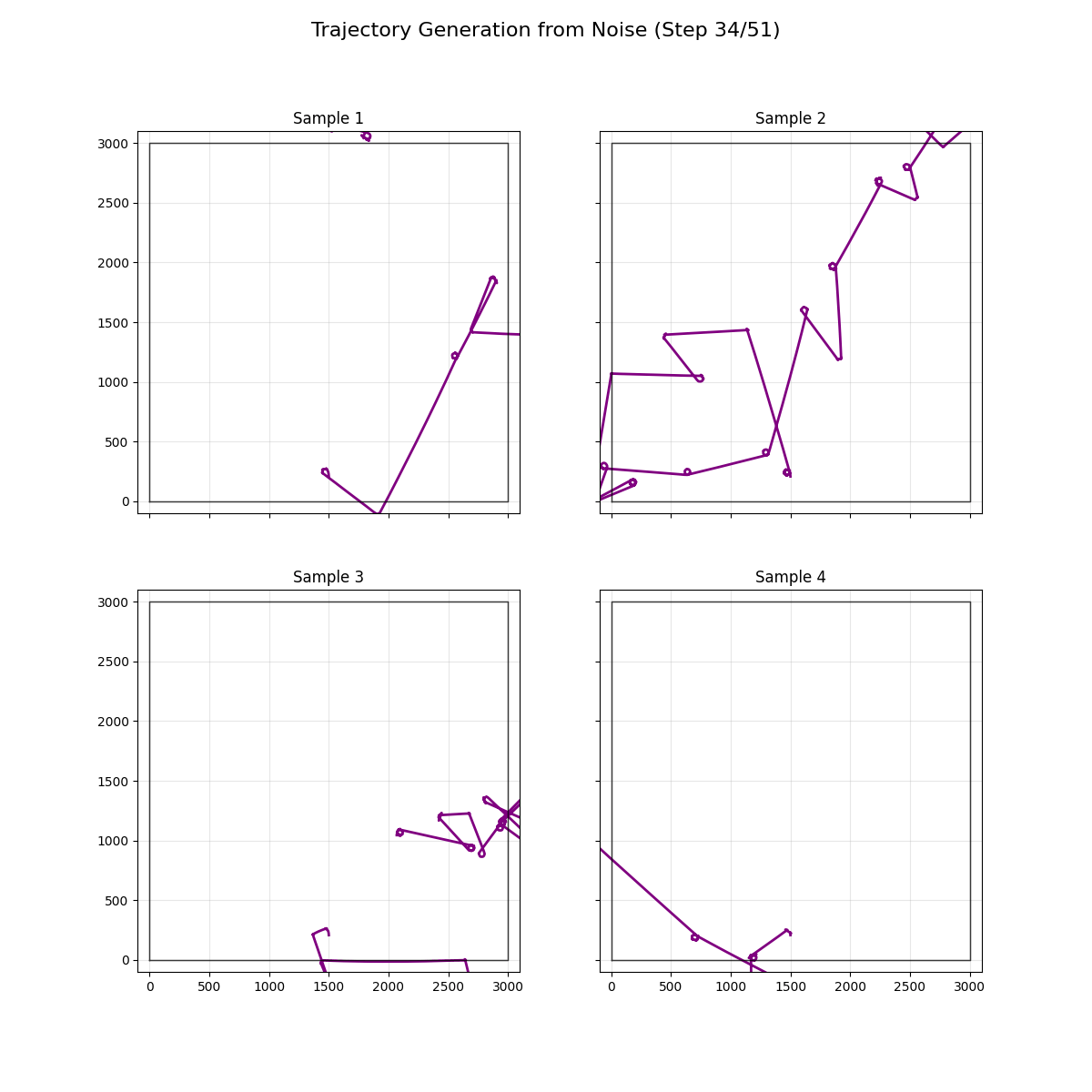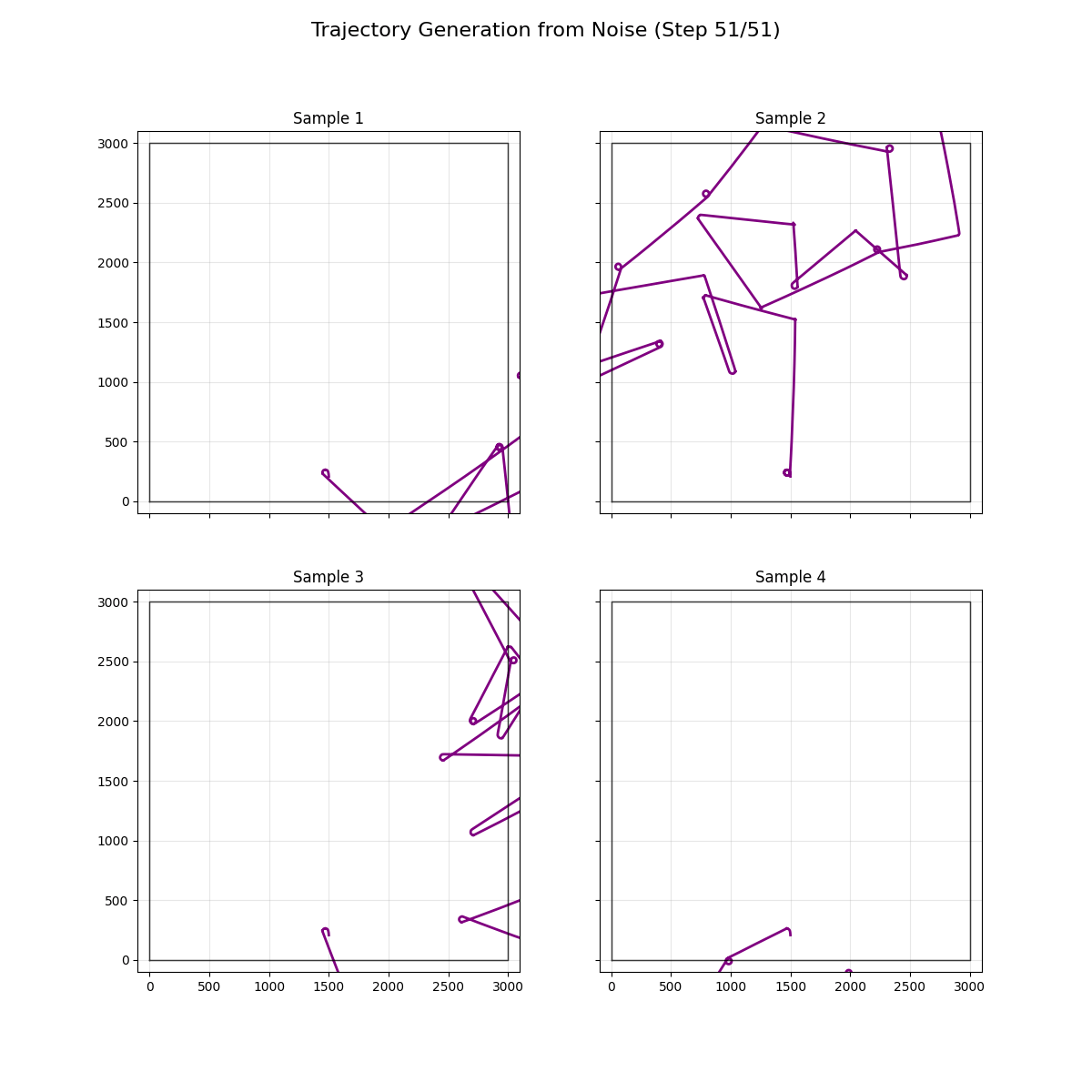
Refactored to demonstrate the noising and denoising process better
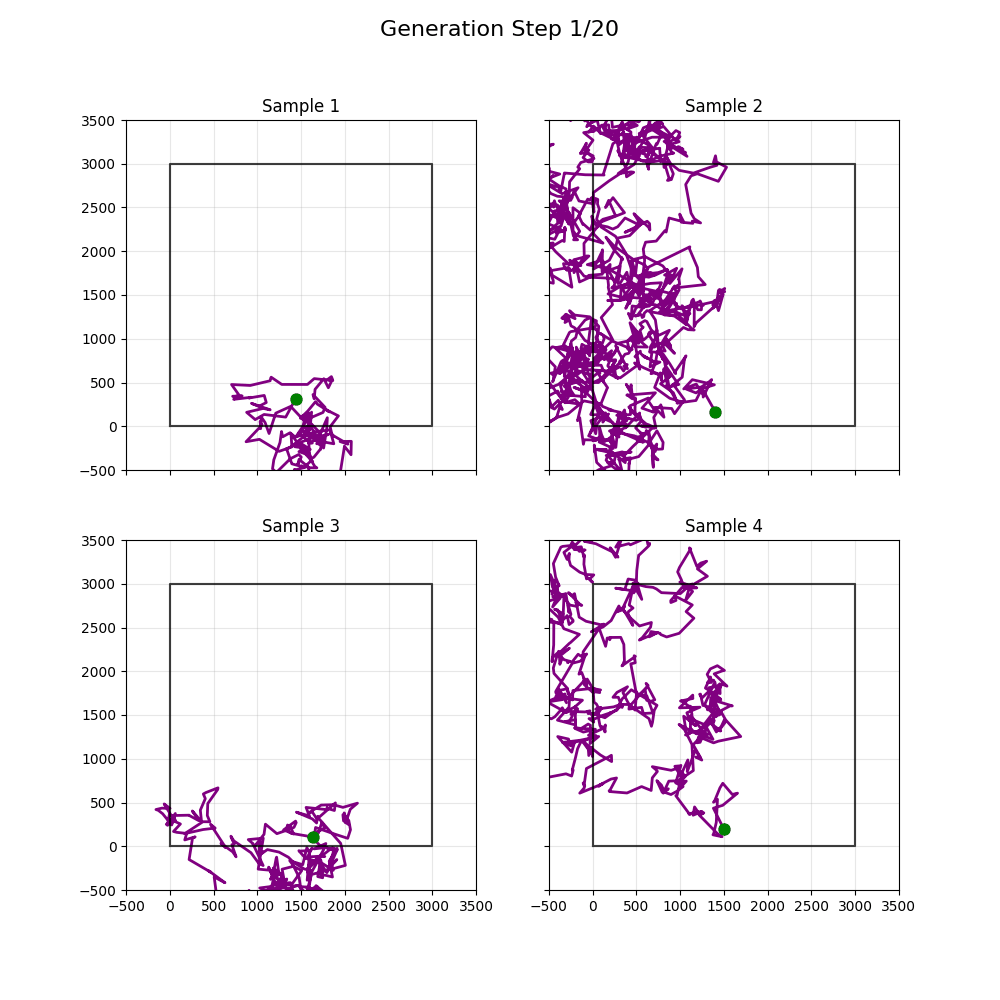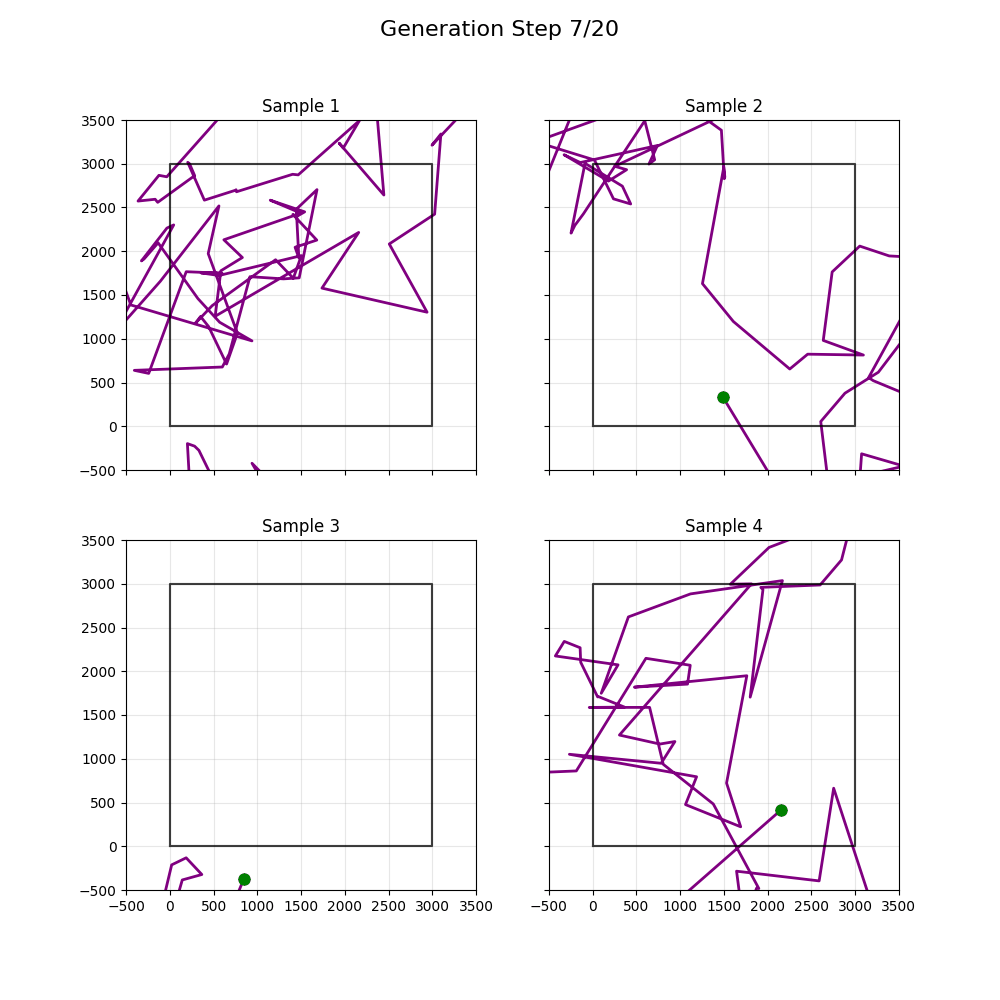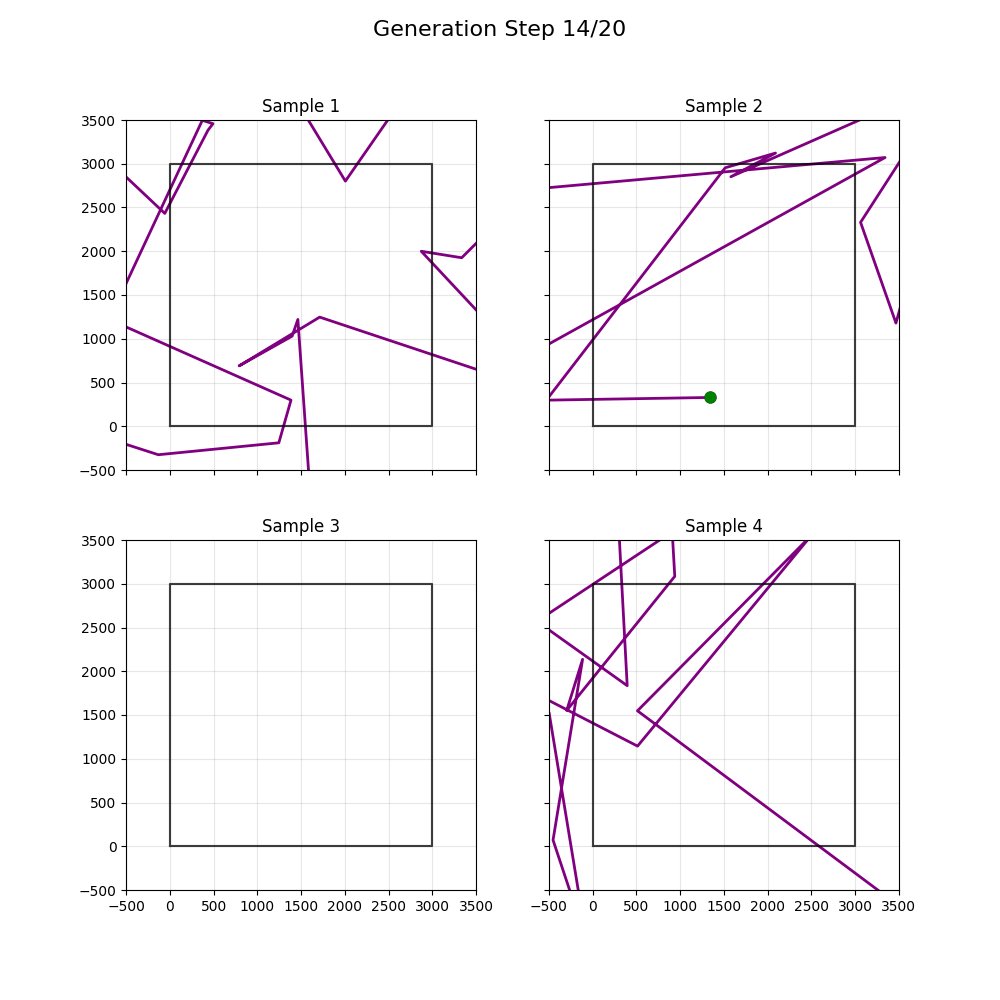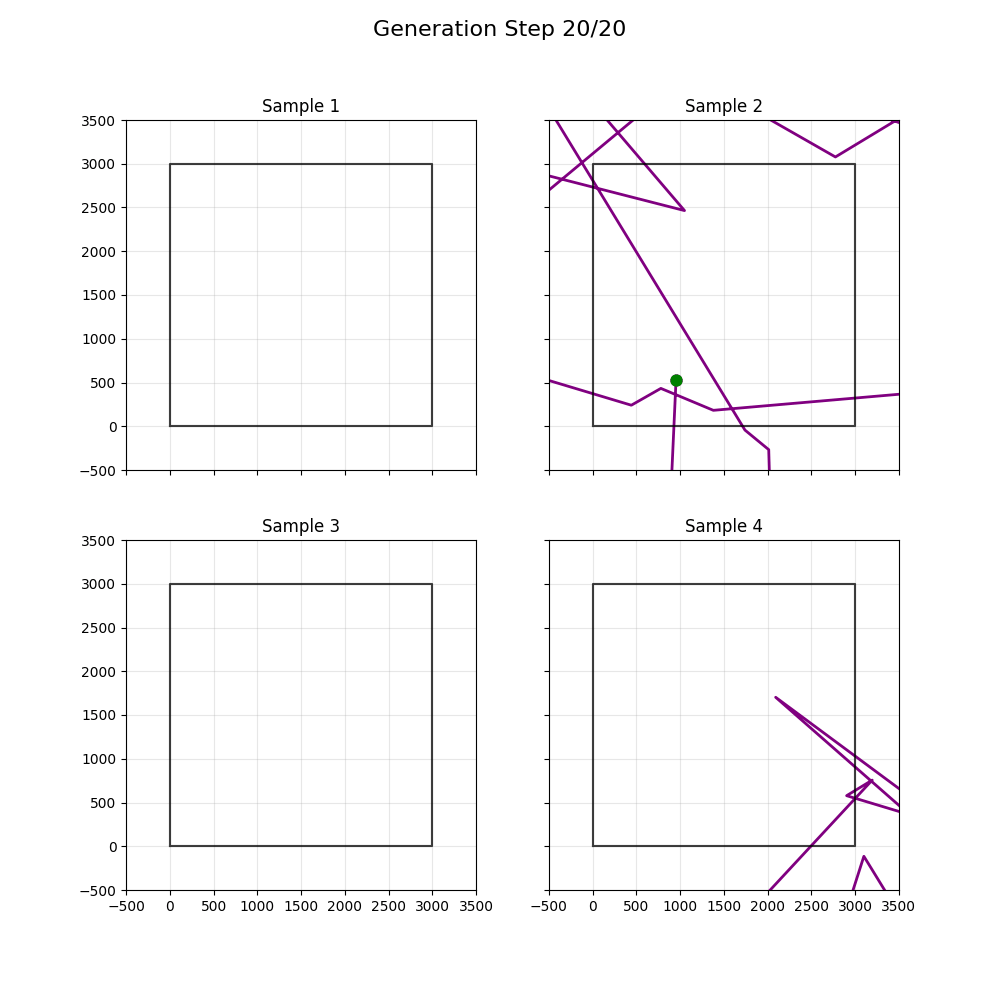
Updated to use more diffuser-y things; didn't help
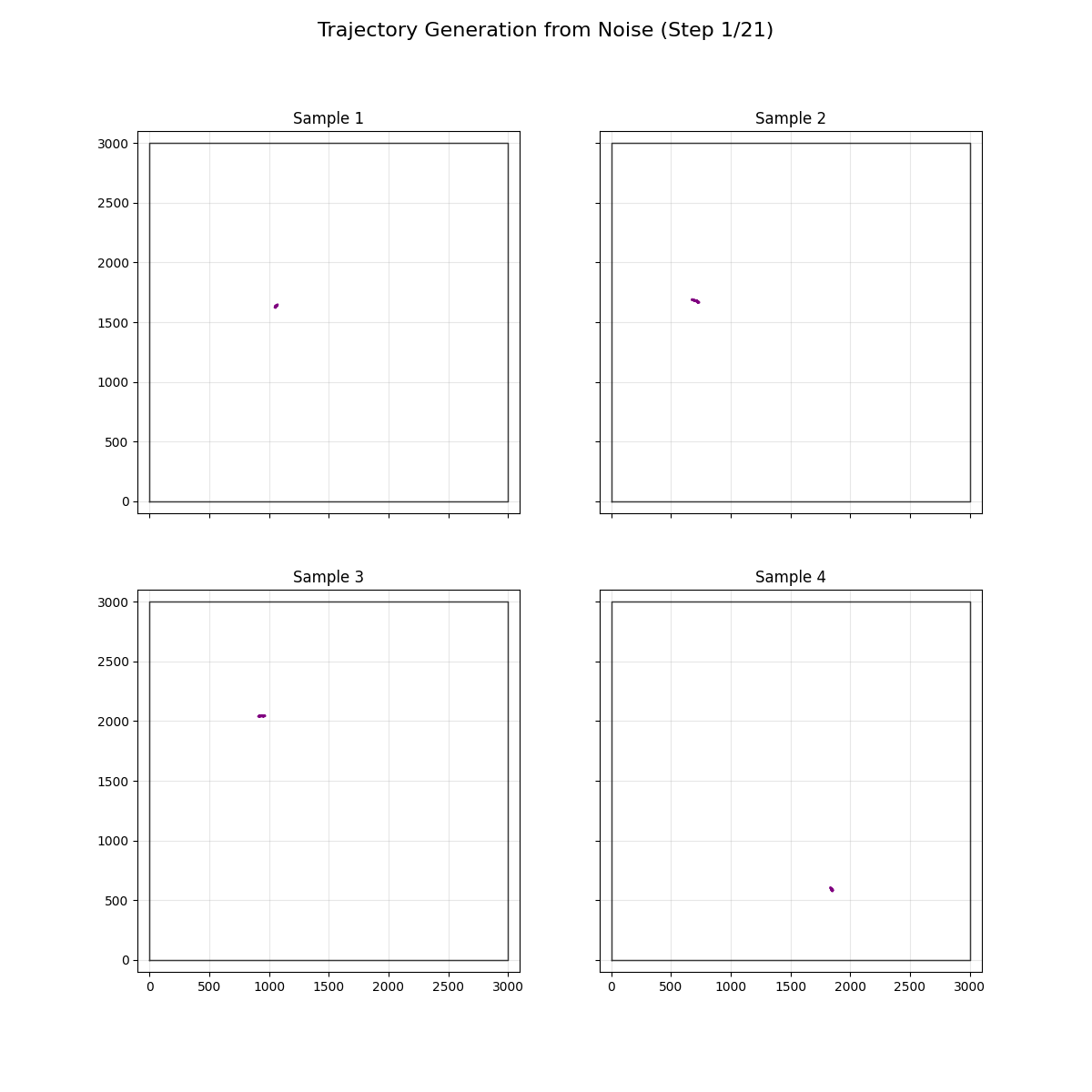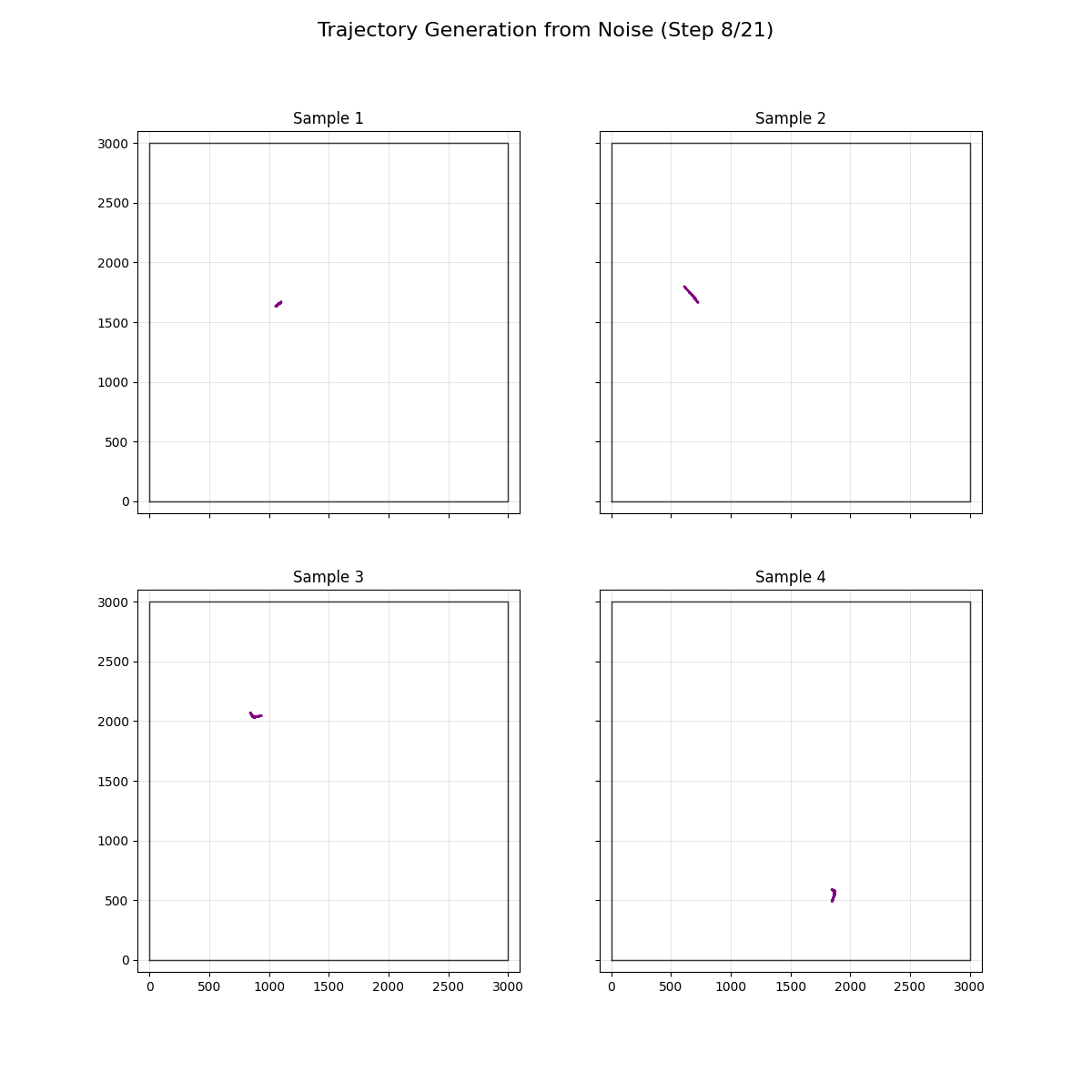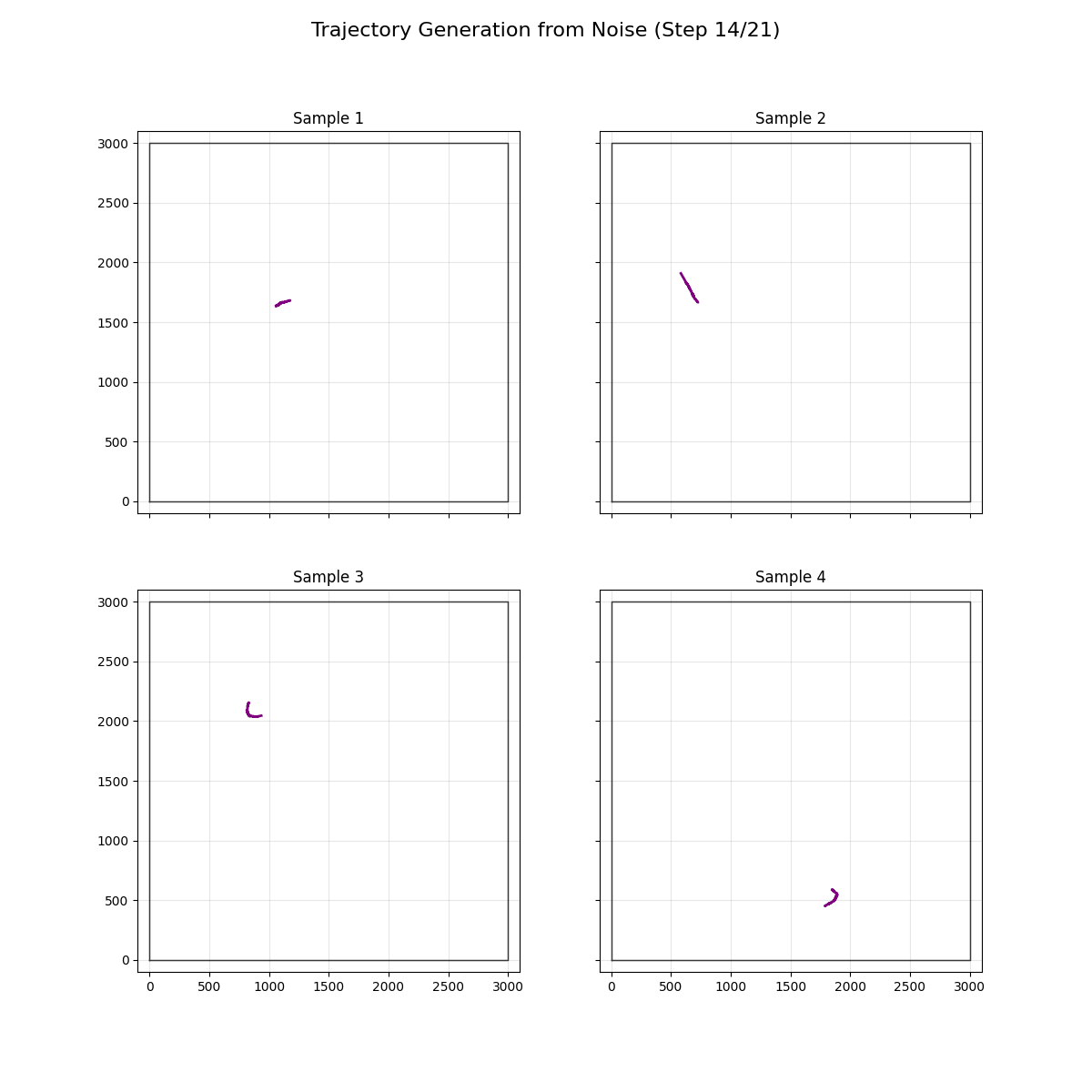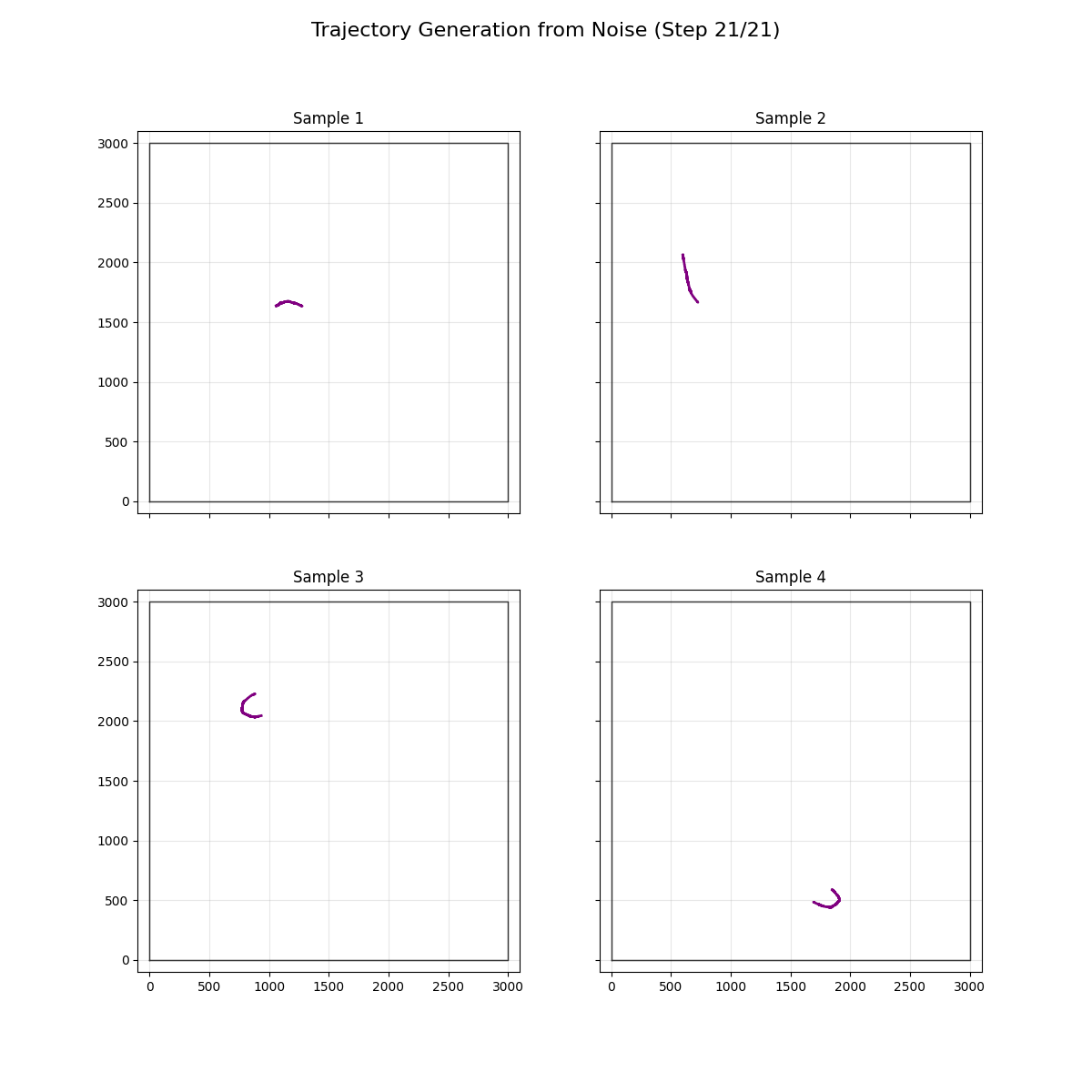
A failure to recreate the first one's success
Uhhh
Yeah