
Qwenflation
Qwen 3 is the latest and greatest LLM from Alibaba. It's amazing on benchmarks and has a wide variety of models, which is why it's very odd that it's so unoptimized. As of May 1st 2025, Qwen 3 is a wide variety of slow models.
Small models
There are some small models that are great for running locally, but they aren't hosted online. The one exception is the 14B, which is more expensive than Phi 4 ($0.07/0.24 vs $0.07/0.14) and slower (91 tps vs 117 tps) when it's the same size.
Medium models
The 32B should be a direct upgrade from Qwen 2.5 32B, Qwen 2.5 Coder 32B, and QwQ 32B. It's not. It's at $0.1/0.3, often more expensive than QwQ ($0.15/0.2) and always more expensive than Qwen Coder ($0.06/0.18). It's also only running at 25-35 tps, half the previous 32B speeds.
Surely the mixture of experts LLM, 30B A3B, will be better. Surely since it has 2B less total parameters and 1/10th of the active parameters it'll run extremely cheaply and fast- what? It's being hosted at only around 60-90 tps? Indeed, it's slower than what you would get on your own 4090 (130 tps per Dubesor), and somehow the same price as both the dense model and another MoE with 3.6x the parameters (Llama 4 Scout).
Large models
The 235B A22B is much smaller than older behemoths like Llama 405B and Deepseek V3, and the current price, $0.2/0.6, reflects that. But should it be lower?
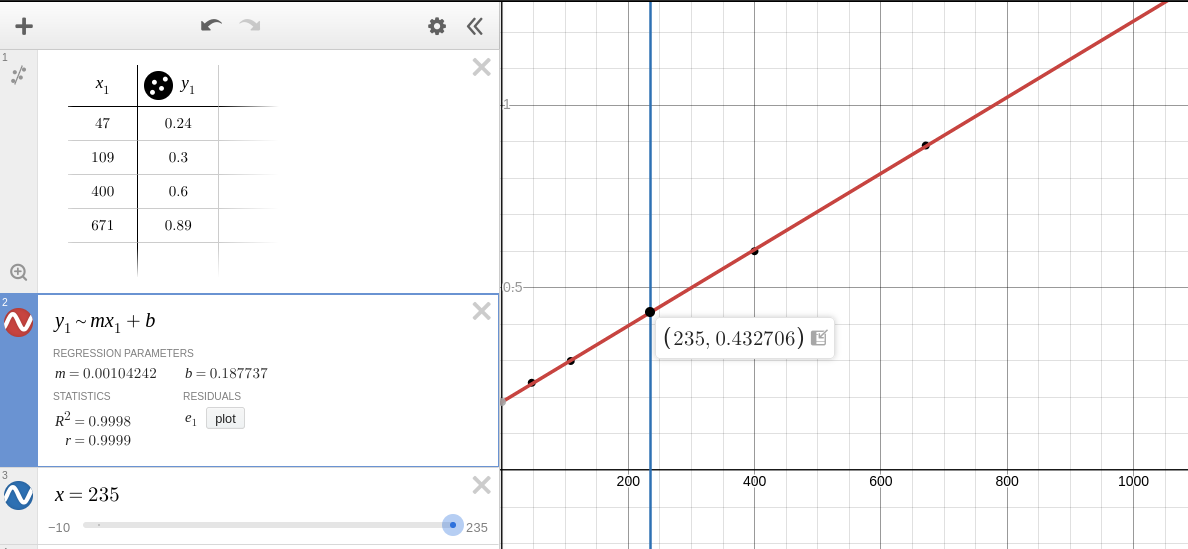
Based on this regression, the current price is about 1.4x what it should be. If you want a model to directly compare to, see Llama 4 Maverick, a larger (400B A17B), cheaper ($0.17/0.6), and faster (90 tps vs 25 tps) model.
Recap
Comparing to other 14Bs, Qwen 3 14B is 171% the price and 72% the speed.
Comparing to other 32Bs, Qwen 3 32B is 167% the price and 46% the speed.
Comparing to the expected 30B MoE, Qwen 3 30B A3B is 137% the price and 60% the speed.
Comparing to the expected 235B MoE, Qwen 3 235B A22B is 139% the price and 28% the speed.
Why?
As I said when I started this post, it's probably just unoptimized and will get better with improvements to inference engines. It might also just need some disruption from DeepInfra price lowering, OpenRouter ad hoc GPU hosting, or Groq/Cerebras/SambaNova running. But the more cynical take is that since Qwen 3 reasons by default, it's subject to the reasoning tax, and it and future generations will never see the same affordability as Qwen 2.5.
2 days later
Things have only gotten stupider. Now, Qwen 30B A3B is:
- more expensive than the 235b version (now $0.1/0.1)
- more expensive than past dense versions (still $0.06/0.18)
- the same price as current dense versions (still $0.1/0.3)
- slower than the free host that's just running sglang
- slower than your own 4090 running ggml (OpenRouter Discord)
I would start a company that just wraps Fly / Hyperbolic / SF Compute / some other GPU provider and hosts it at a better price, except I don't really want to figure out taxes and registration and all that.